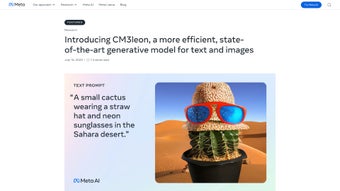
CM3leon:テキストと画像生成のための高度なAI
CM3leonは、シームレスなテキストから画像、画像からテキストの生成のために設計された最先端の生成AIモデルです。このマルチモーダルモデルは、低いトレーニングコストで効率的に動作し、最先端のパフォーマンスを提供します。自己回帰機能を統合することにより、CM3leonはさまざまな入力に基づいて一貫した画像とテキストのシーケンスを生成する能力で際立っています。このモデルのトレーニングには、リトリーバル拡張事前トレーニングなどの革新的な技術が含まれており、さまざまなタスクにおける能力を向上させています。
最もおすすめの代替ソフト
特に、CM3leonは複雑なオブジェクト生成とテキストガイドの画像編集に優れており、Googleのテキストから画像モデルを含む以前のモデルを上回り、驚異的なFréchet Inception Distance (FID)スコアを達成しています。そのマルチタスク指示チューニングは、画像キャプション生成や視覚的質問応答などのタスクにおけるパフォーマンスを大幅に向上させます。小さなデータセットでトレーニングされているにもかかわらず、CM3leonは印象的なゼロショットパフォーマンスを示し、さまざまな視覚言語アプリケーションにおけるその多様性と効果を示しています。